特徵是用來區分不同物體的依據,統合許多不同的特徵來做出分類決策的程序則稱為分類器。機器學習的目的就是要找出特徵與特徵之間的關係,並加以組合後,得到正確的結果。
例如在判斷一個人是男生還是女生的時候,可能會採用頭髮、鬍子、衣著、身形等特徵,並將這些特徵轉換成數學形式後,得到一個男生或女生的結論。
機器無法理解語意型的特徵,因此在定義特徵時,最好使用可量化的資訊作為特徵。
同樣的特徵在不同問題中可能有不同的效果,例如機車與腳踏車的比較中,輪子數這個特徵就不適用了。
通常生活中遇到的問題都比較複雜,難以只使用單一特徵來做區分,所以我們會使用多個特徵。例如,有兩個特徵15和3,在數學上就會表示成(15, 3),這種表示法稱為向量表示法。由於這些向量的本質都是特徵,所以也稱作特徵向量。
轉換成特徵向量後,它已經是一個數學表示法。假設有兩個特徵 (x_1) 和 (x_2),那每個特徵向量就是這個座標平面上的一個點,這些特徵向量所在的空間,稱為特徵空間。機器要學習的是如何在這個特徵空間中正確地區分所有樣本。
例如,下圖中,機器會找到中間那條藍色的線,並學成了一個分類器。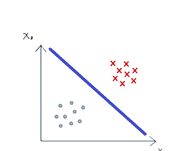
電腦看到的圖其實是一堆代表顏色的RGB數字,所以它學習的是這些數字與大象之間的關聯性。
每個畫素(pixel)都會有顏色資訊RGB,例如8x8的手寫數字圖像就有64個點,如果是彩色圖像就會有RGB三個值。對於灰階影像,只有亮度資訊,這些數字通常會先攤平,意思是將8x8轉成1x64的向量,這樣已經轉成向量的形式,就可以交給機器學習。
事實上,我們並不知道究竟要多少特徵,通常是通過多次實驗來測試和調整。
不一定。有時候錯誤率低並不代表模型好。例如在做癌症檢測時,如果預測所有人都沒有癌症,雖然會有很高的準確率,但顯然這是不好的。我們希望只要有癌症的可能性就要檢出來,所以錯誤率低並不一定是一個好模型。

